Building a Bot to Filter Out Repetitive Emails
Last June, I built a website for my climbing club, Adrénaline Escalade, to fully automate member subscriptions. Despite having an extensive Q&A section, we received a significant number of emails containing questions that could have been quickly answered if people had taken the time to look through the Q&A.
So I thought: Why not feed the questions asked through the contact form to a Large Language Model (LLM) that could understand the question and provide the best possible answer? If the user is not satisfied with the answer, they could then send the question to a human being for further clarification. If this approach could filter out even half of the questions received, it would significantly relieve the administrative burden.
Retrieval Augmented Generation
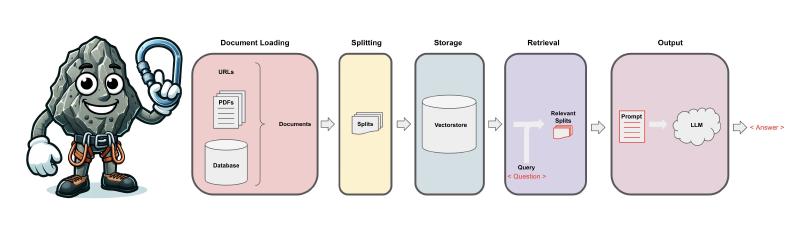
After some research, I quickly realized that the easiest way to use LLMs for Question & Answering with your own data is to employ a technique called Retrieval Augmented Generation (RAG). This approach combines the power of large pre-trained language models with your own curated knowledge sources to enhance the capabilities of the language model.
If you’re unfamiliar with how RAG works at this stage, search for “What is RAG?” videos on YouTube to understand the concepts of embeddings and vector databases. If you’re a French reader, check out this excellent blog post from OCTO: Construire son RAG grâce à Langchain: L’exemple de l’Helpdesk d’OCTO
Langchain… Or Not
Like most online tutorials, this article explains how to use Langchain to implement a RAG. Langchain is often referred to as the Swiss Army knife for Large Language Models (LLMs). However, it’s so comprehensive and powerful that it can be intimidating, especially if you only have a few hours to spend on the topic as a hobbyist.
Embedchain to the Rescue
Embedchain promises that you can start building LLM-powered apps in under 30 seconds, and that’s nearly true (it took me just a few minutes). Embedchain is actually a wrapper around Langchain, which in turn is a wrapper around LLMs. It dramatically simplifies the whole RAG process by automatically processing unstructured data, breaking it into chunks, generating embeddings, and storing them in a vector database.
You can add various sources of knowledge (websites, text files, Q&A pairs, etc.) using the .add() method. Then, you simply pose your question using the .query() method. Could it be any simpler?
import os
import json
from dotenv import load_dotenv
from embedchain import App
# Load the .env file containing your OPENAI_API_KEY
load_dotenv()
# Initialize embedchain app
climbing_bot = App()
# Embed some general knowledge about climbing from Wikipedia
climbing_bot.add("https://fr.wikipedia.org/wiki/Escalade")
climbing_bot.add("https://fr.wikipedia.org/wiki/Mouvements_d%27escalade")
climbing_bot.add("https://fr.wikipedia.org/wiki/Vocabulaire_de_l%27escalade_et_de_l%27alpinisme")
# Embed pages from the Adrénaline website (describing the club, the gymnasiums, etc...)
climbing_bot.add("https://www.adrenaline-escalade.com/")
climbing_bot.add("https://www.adrenaline-escalade.com/bureau/")
climbing_bot.add("https://adrenaline-escalade.com/gymnases/")
# Embed the site Questions & Answers stored in JSON
# Embedchain has a convenient data_type for qna pairs
file_path = './Adrenaline_Escalade_FAQ.json'
faq_tuples = [(item.get('question', ''), item.get('answer', '')) for item in json.load(open(file_path, 'r', encoding='utf-8'))]
for qna_pair in faq_tuples:
climbing_bot.add(qna_pair, data_type="qna_pair")
# Start chatting...
answer = climbing_bot.query("A partir de quel âge est-il possible de s'inscrire ?")
print(answer)
# --> "Il est possible de s'inscrire à partir de 5 ans et demi dans les cours ouistitis."
answer = climbing_bot.query("Est-il possible de payer en plusieurs fois ?")
print(answer)
# --> "Non, il n'est pas possible de payer en plusieurs fois."
And Dall-E generated a nice avatar for my bot 😃

Have fun with LLMs 🧠 🤖 !